I lead the Safeguards Research Team at Anthropic. We’re developing technical solutions to mitigating risks from AI, including frontier model safeguards, advanced post-deployment monitoring techniques, and automated red-teaming. See my Google Scholar profile for my recent work, with some highlights below.
…
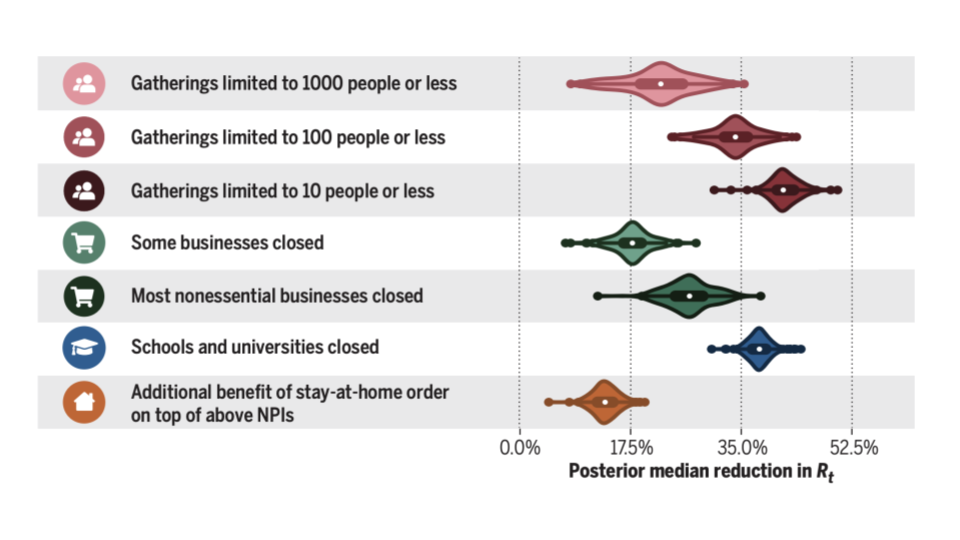
Before joining Anthropic, I obtained my PhD from the University of Oxford in the Autonomous Intelligent Machines and Systems programme. I had the good fortune of being supervised by Tom Rainforth, Eric Nalisnick, and Yee Whye Teh. The first portion of my PhD was spend developing Bayesian models to evaluate the effects of nonpharmaceutical interventions on COVID-19 transmission. My work on this topic has been cited in federal legislation, presented to the Africa CDC modelling group, and shared with the UK’s Scientific Advisory Group for Emergencies. Following that, I worked on accelerating model training using ideas from probabilistic modelling, rethinking Bayesian neural networks, and understanding sycophancy in language models.
Even before that, I obtained a Masters in Information and Computer Engineering from the University of Cambridge, where I graduated top of my cohort. My final year project was on Bayesian Inference and Differential Privacy.

Constitutional Classifiers

Best-of-N Jailbreaking

Rapid Response: Mitigating LLM Jailbreaks with a Few Examples

Many-shot Jailbreaking

Towards Understanding Sycophancy in Language Models

Do Bayesian Neural Networks Need To Be Fully Stochastic?